Aker Solutions
.avif)
Aker’s product platforms accelerate cloud and data transformation in complex, regulated environments—giving teams the infrastructure, automation, and governance needed to modernise with confidence and control.


.avif)
.avif)
.avif)
.avif)
.avif)
.avif)
.avif)
.avif)


AI-Ready Data Infrastructure: What It Really Means for Government and National Security Organisations


The AI Readiness Gap in Government
There is a widening gap between AI ambition and AI capability in government. Investment in large language models, machine learning platforms, and intelligent automation tools is accelerating — yet many organisations find that AI pilots fail to scale, produce unreliable outputs, or are blocked entirely by data quality and access issues.
The root cause is consistent: AI does not fail because the models are inadequate. It fails because the data underpinning those models is not trusted, not accessible in real-time, not well-governed, or not structured to support machine consumption. As leading practitioners observe, AI models amplify whatever foundation they sit on — if data is inconsistent, siloed, or semantically unclear, AI outputs will reflect those weaknesses at scale.
The distinctive challenges of public sector data
Government and national security organisations face data challenges that are more acute than those found in commercial sectors:
- Legacy systems spanning decades of technology generations, often without integration or standardised data formats, and frequently lacking the Change Data Capture (CDC) capability needed to feed AI in real time
- Strict data classification and handling requirements that limit sharing and access even within the same organisation, requiring fine-grained, attribute-based access controls embedded in the data infrastructure
- Disconnected data silos across departments, agencies, and operational units — causing what practitioners describe as context starvation in AI systems that need to reason across domains
- Limited real-time data availability, with many critical datasets updated on batch cycles measured in hours or days, making them structurally unsuitable for operational AI
- High consequence environments where data errors carry operational, reputational, or national security risk, and where AI outputs must be explainable and auditable under scrutiny
The Evidence Base
Approximately 80% of organisations report that inconsistent or duplicated data directly hinders AI delivery. Only 14% have a fully AI-ready data platform. Without addressing the data foundation first, AI investment compounds existing problems rather than solving them.
What AI-Ready Data Infrastructure Actually Means
'AI-ready' has become an overused term. For the purposes of this paper, we define AI-ready data infrastructure as the combination of technical architecture, data management practices, and governance frameworks that enable AI systems to consume, process, and act on trusted data — reliably, securely, and at the speed operations demand.
It is important to distinguish this from traditional analytics architecture. Legacy systems were designed to support human-readable reports and dashboards. AI-ready infrastructure is designed for machine consumption — where data must be discoverable, governed, secure, and semantically structured so that AI operates on consistent meaning, not raw tables.
The five dimensions of AI readiness
True AI readiness has five interconnected dimensions. Each is necessary; none is sufficient alone:
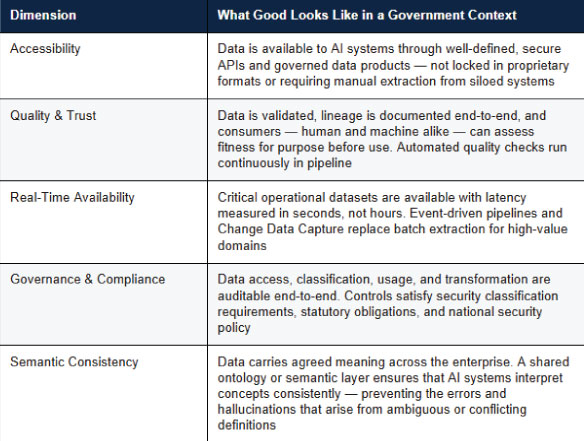
The fifth dimension — semantic consistency — deserves particular emphasis. Many architecture frameworks focus on the technical plumbing of data infrastructure and underweight the meaning layer. In government, where the same term (citizen, incident, asset) may be defined differently across departments, the absence of semantic consistency is a direct cause of AI unreliability.
Why Real-Time Data Is Non-Negotiable
Many government organisations have invested significantly in data warehouses and reporting platforms that provide excellent retrospective insight. These are valuable. But AI systems — particularly those supporting operational decisions — require something fundamentally different: access to current state.
In national security, emergency response, border management, and defence logistics, the difference between data that is minutes old and data that is seconds old can determine whether an AI-generated insight is actionable or irrelevant. Static batch architectures, however well-designed, cannot meet this requirement. As practitioners in this field put it: AI and agentic workloads cannot wait for nightly syncs.
The architectural shift that makes real-time possible
AI-ready organisations are moving from batch extraction models to event-driven data architectures that propagate changes across the enterprise as they occur. This shift involves several interconnected components:
- Streaming data pipelines (using technologies such as Apache Kafka or Azure Event Hubs) that capture and distribute change events in near real-time
- Change Data Capture (CDC) mechanisms that sync operational databases continuously rather than on scheduled intervals, ensuring AI systems work from the latest state
- Lambda or Kappa architecture patterns that handle both batch historical data and real-time streams — providing a unified view across historical context and current events
- API-first data product design that enables controlled, auditable consumption by AI systems without requiring direct database access
- Data virtualisation layers that provide a unified, real-time view across heterogeneous sources without moving data unnecessarily — particularly important given sovereignty constraints
For government technology leaders, this architectural shift must be navigated alongside legacy modernisation — it is rarely a greenfield opportunity. The most effective approaches create incremental pathways that deliver real-time capability on priority data domains first, rather than attempting wholesale replacement.
Data Governance as a Strategic AI Enabler
In regulated environments, governance is often perceived as a constraint on AI adoption. The reality is the opposite: rigorous data governance is what makes AI adoption possible at scale. Without a clear understanding of what data exists, where it originated, how it has been transformed, and who is authorised to use it — no AI system can be safely deployed in a high-consequence context.
Critically, governance must be embedded in the data itself, not just documented in policy. Cataloguing data without enforcing policies is insufficient. Organisations that treat governance as code — classifying data at source, enforcing encryption and masking rules in the pipeline, and automating audit trails — consistently outperform those that rely on manual controls.
The governance components that matter most for AI
- Data cataloguing and lineage: AI pipelines — including model training workflows — need to understand the provenance and transformation history of every dataset they consume. Tools such as Apache Atlas and OpenLineage provide this foundation, and lineage is essential for debugging model drift and satisfying audit requirements
- Semantic governance: A shared enterprise ontology or semantic layer that defines core concepts and their relationships across the organisation, ensuring AI systems interpret data consistently regardless of source system
- Access control and classification: Fine-grained, attribute-based access controls ensure AI systems can only consume data appropriate to their security context — with policies embedded at the platform level rather than relying on perimeter controls
- Automated data quality scoring: Continuous quality assessment using frameworks such as Great Expectations or Deequ enables AI systems to factor confidence levels into their outputs and surfaces degradation before it affects operational decisions
- Audit and explainability: When regulators, ministers, or operational commanders ask how an AI-generated decision was reached, the answer depends entirely on governed, documented data with end-to-end traceability
The Aker Perspective
Effective data governance is not a project with an end date — it is an operating discipline. Organisations that treat it as a one-time compliance exercise consistently struggle to scale AI beyond pilots. Governance must be designed into the data architecture from the outset, not retrofitted.

Security and Sovereignty in AI Data Infrastructure
For national security and defence organisations, data infrastructure decisions carry sovereignty implications that go beyond conventional enterprise risk. Questions of where data resides, who can access it, how AI models are trained on sensitive material, and how outputs are controlled require careful architectural planning that commercial frameworks often do not address.
Core design principles for secure AI-ready infrastructure
- Classify before you compute: Data classification must be embedded in the data pipeline — not applied retrospectively — to prevent sensitive data from being inadvertently exposed to AI systems operating at lower classification levels. Real-time masking of sensitive fields in transit is now a practical capability, not a theoretical aspiration
- Zero-trust data access: Every interaction between AI systems and data assets must be authenticated, authorised, and logged — regardless of network location. This is particularly important as AI pipelines often involve automated processes that traditional perimeter controls do not adequately govern
- Sovereign deployment options: AI-ready infrastructure must support deployment in on-premises, private cloud, or sovereign cloud environments without architectural compromise. The storage and compute layer must be separable from the data access and governance layer to support classified environments
- Model isolation and auditability: Where AI models are trained on sensitive data, training environments must be isolated and auditable, with appropriate controls on model extraction and deployment. The lineage from training data to deployed model must be traceable
- Federated approaches where appropriate: In environments where data cannot be centralised — whether for classification, legal, or sovereignty reasons — federated data access and federated learning techniques allow AI to benefit from distributed data without violating handling requirements
These are not theoretical requirements. As government AI programmes mature, they will face scrutiny from security authorities, the National Cyber Security Centre, audit bodies, and parliamentary oversight. Infrastructure decisions made today will determine whether those programmes can withstand that scrutiny.
A Practical AI Readiness Framework
Based on Aker's experience delivering enterprise data modernisation programmes for regulated public sector clients, and informed by industry research from organisations including EY, Gartner, and HyperFRAME, we have developed a five-stage AI Readiness Framework that provides a practical basis for assessing current capability and prioritising investment.
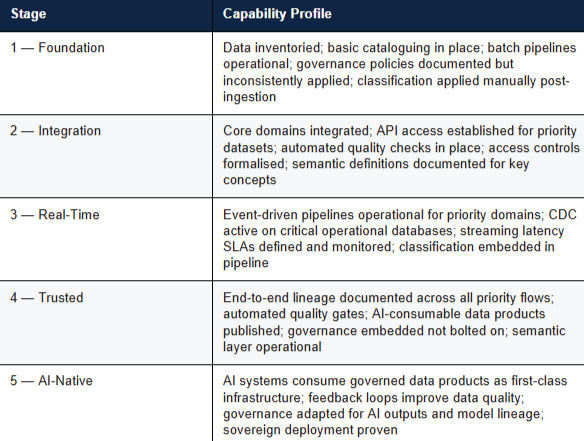
Most government organisations sit between Stages 1 and 2.
The priority for technology leaders should be to establish the integration and governance foundations that allow progression to Stage 3 — real-time capability — where AI applications begin to deliver meaningful operational value.
The journey from Stage 2 to Stage 3 is where architecture decisions have the greatest long-term impact.

A Phased Roadmap for Technology Leaders
Building AI-ready data infrastructure is a multi-year endeavour. The foundational decisions made in the first twelve months disproportionately determine long-term outcomes. The following phased approach reflects both industry best practice and the specific constraints of regulated government environments.
Phase 1: Assessment and Planning (0–3 months)
Before any architecture decisions are made, conduct an honest audit of the current data estate: what data exists, where it lives, what condition it is in, how it is classified, and what the priority operational use cases for AI actually are. Deliverables at this stage should include a current-state report, a prioritised list of AI use cases with their data requirements, and a high-level architecture blueprint. This phase is frequently underinvested in — organisations that shortcut it consistently encounter avoidable problems downstream.
Phase 2: Foundation Build (3–6 months)
Establish the core data infrastructure on priority domains: a governed data platform (lakehouse or equivalent) with appropriate security controls, initial streaming and CDC pipelines on high-value data sources, a data catalogue with active lineage tracking, role-based and attribute-based access controls, and the beginning of a semantic model for the most critical business concepts. Resist the temptation to boil the ocean — concentrate investment on the two or three data domains that will unlock the most valuable AI use cases.
Phase 3: Pilot AI Use Cases (6–9 months)
Deploy the first AI applications against the governed data foundation. Implement monitoring for data quality, pipeline health, and — once models are running — model performance and drift. Establish the MLOps practices (data versioning, automated retraining triggers, deployment pipelines) that will be needed at scale. This phase validates the architecture and surfaces gaps before they become expensive to fix.
Phase 4: Scale and Govern (9–18 months)
Expand the architecture to additional data domains, enforce governance across all pipelines, roll out the semantic layer to further business concepts, and train teams on new practices and tools. Build the ROI reporting that will maintain executive and programme support as the programme moves from visible pilots to background infrastructure.
A note on procurement
AI-ready infrastructure is not a single platform purchase. Organisations that approach it as a product procurement exercise consistently underestimate the data engineering, governance, and change management work required. Technology enables readiness — but architectural discipline, skilled teams, and sustained leadership attention are what deliver it.
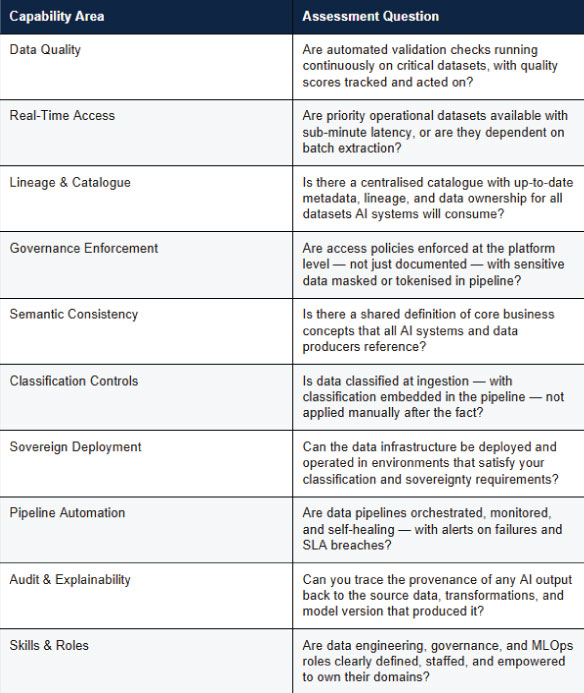
AI Readiness Self-Assessment
The following checklist — adapted from industry frameworks and Aker's programme experience — provides a practical basis for assessing AI data readiness in a government context. Any gap identified here represents a priority for investment before AI deployment at scale.




Conclusion
The organisations that will lead on AI in government and national security are not necessarily those with the largest AI budgets or the most advanced models. They are those that have done the disciplined, often unglamorous work of building trusted, accessible, real-time, and semantically consistent data infrastructure.
AI amplifies whatever data capability sits beneath it. If that data is fragmented, untrusted, semantically ambiguous, or inaccessible in real-time — AI amplifies those problems. If it is governed, integrated, meaningful, and current — AI amplifies the value of that investment many times over.
The question for technology leaders is not whether to invest in AI-ready data infrastructure. It is how to sequence that investment to deliver operational value quickly, while building the foundations for sustainable capability at scale — and doing so in a way that will withstand the security, legal, and accountability scrutiny that public sector AI programmes will inevitably face.
Aker is a UK-based enterprise data modernisation specialist with deep expertise in regulated public sector environments, including central government, national security, and defence. We work with Data and Technology leaders to design and deliver the data infrastructure that trusted AI depends on — from architecture and governance to real-time pipelines and sovereign deployment.
Email us at enquiries@akersystems.com or use our online enquiry form.
See how Aker can help you modernise data securely
Get in touch to book a discovery call.






.avif)

